Optical Character Recognition for .NET
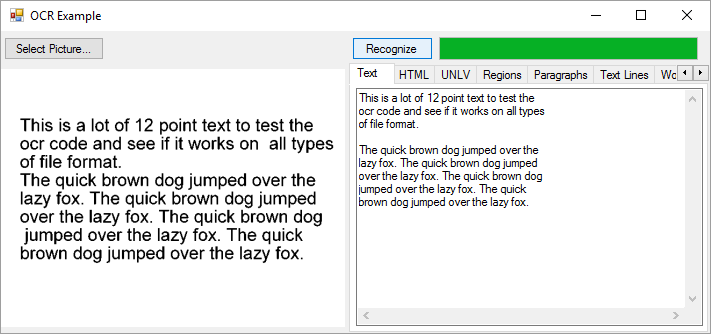
Use this OCR component to extract text from images, such as scanned paper documents or other image-based files.
- powered by the Tesseract OCR engine and the Leptonica image processing library
- compatible with .NET Framework 4.8 and .NET 8
- includes source code with the registered version
- offers royalty-free distribution for your applications
Download Tesseract language data and place to tessdata folder.
Order OCR.NET component $100 USD (single developer license)
Order OCR.NET multi-license $300 USD (license for all developers in the company)
Order OCR.NET year upgrades $50 USD (registered users only)
Order OCR.NET year upgrades multi-license $150 USD (registered multi-license users only)
FAQ
Why am I encountering the error "An unhandled exception of type 'System.BadImageFormatException' occurred in Winsoft.Ocr.dll"?
This error occurs when the incorrect ocr.dll library is being used, such as attempting to use a 32-bit library in a 64-bit environment or vice versa.To resolve this issue: place place the appropriate ocr.dll in the folder where your application's executable file (.exe) is located:
32-bit ocr.dll is located in the DLL\32bit subfolder.
64-bit ocr.dll is located in the DLL\64bit subfolder.